ubuntu下实用svnserve配置svn服务器
2010-07-31
TextMate里面有很多实用的Bundle(扩展包)。其中对Javascript语言有一个美化(调整格式)JS代码的功能,是调用TextMate自带的一个php脚本来实现的。
这个扩展功能本身是很好用的,不但可以美化整个文档,还可以美化选中的js代码片段。 但是有个不大不小的也算不上上面bug的bug,就是美化过的代码缩进全部使用空格,而不是我们常用的tab。 这个问题有时候是很烦人的。。所以就自己动手改了一下。下面是修改过程:
完。
暑假和女朋友住在她们学校的教师公寓。上网成了大问题,困扰了我好久。最后总算找到了解决方法。。。。
川外成都学院位于成都西郊,整个校园有且只有校园网,60元包月(512K带宽)。整个校园覆盖了电信wlan(ssid:ChinaNet),不要密码,连上后上非电信网站需要登录(3元/小时)。宿舍周边很少wifi热点。
首先按照常规考虑校园网,但是暑假学校停止办理。。。
然后考虑去找电信装宽带。营业厅MM告诉我不能装,于是投诉到10000号,纠结几天后,还是没办法装。。。(估计是电信和学校达成某种协议,学校里面只能用校园网)。。。
然后考虑通过手机的3G网络带电脑上网。 手机系统是android,没有网络共享方案,于是购买了一个叫做pdanet的软件(貌似$18.9)。开始使用手机共享给电脑上网。但是有缺点: 1.接电话的时候无法上网。 2.资费贵:50元1GB流量,100元2GB 。。。贵死了 3.电脑控制流量困难: 经常趁我不注意的时候,某个程序自动去下载更新。一下就是几十上百MB。。4.夏天手机发热严重,担心影响手机寿命
然后尝试电信的wlan。手机套餐每月赠送3小时wlan时间。 连上ChinaNet无线网后,可以上 www.sc.ct10000.com 和电信的几个站点。 于是想到能不能拿到其中一个站做代理就爽了! 在连上wlan没有登录的情况下寻觅许久,终于发现一个站有注入漏洞~~几经周折通过MSSQL漏洞建了个超级管理员确无法登录。。再次纠结许久之后发现数据库服务器和网站的Web服务器分开的!!
在连上wlan没有登录的情况下寻觅许久,终于发现一个站有注入漏洞~~几经周折通过MSSQL漏洞建了个超级管理员确无法登录。。再次纠结许久之后发现数据库服务器和网站的Web服务器分开的!! 之后几天一直在找另外的方法,之后被我发现网站后台编辑器有上传任意文件的漏洞~再次狂喜。 传了个asp webshell上去,确发现无法执行cmd命令。再传个php webshell上去,发现还是无法!!
之后几天一直在找另外的方法,之后被我发现网站后台编辑器有上传任意文件的漏洞~再次狂喜。 传了个asp webshell上去,确发现无法执行cmd命令。再传个php webshell上去,发现还是无法!!
没办法,只好放弃拿管理员权限。既然可以传任意文件,那我就搞个php代理吧。照样可以上网。 几天后,搞了个php代理,大概的实现方式是这样的:
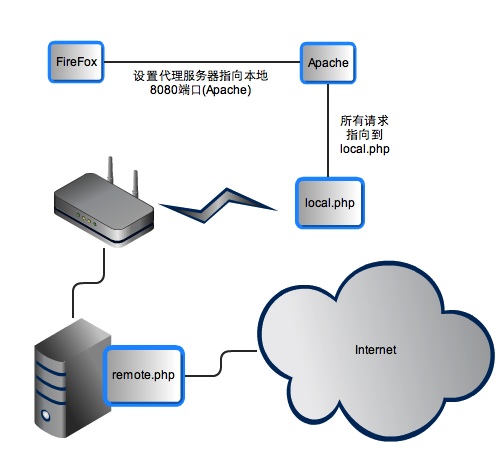
通过firefox发送http请求到本地的apache端口,apache收到请求后交给local.php脚本处理。 local.php脚本把firefox发过来的http头信息封装发送到远程服务器的remote.php。remote.php再解释local.php发过来的头信息,得到要访问那个服务器。然后去目标服务器取数据,按原路返回。
虽然这是一个非常复杂的过程,但是在做这个代理方案的过程中我学到了很多东西,包括HTTP 1.1的一些协议的东西。
这个代理做的比较成熟了。可以访问绝大部分网站,也可以看视频。但是无法上QQ等,只能看网页。 而且代理服务器有防火墙,如果并发连接太多了,我的IP就会被封。。。。所以上网的速度也不能很快。 还是无法满足我的需求。
后来无意发现 anywlan.com这个论坛。 于是想自己做个天线蹭别人的网上。 由于这个方案太复杂,所以到目前还没有实施。。。后来又看到远距离无线网桥这个东西,据说距离可以达到30KM。那岂不是可以在我的学校(电子科技大学)放一个,在这边放一个,就可以用电子科大的网络来上网了?不过设备价格太贵,而且我很难安装到楼顶。。。这个方案更不可行。
再后来运用上学期学到的接入网知识,想到一个方案: 正好一个朋友住在宿舍旁边的教师公寓,他们很早以前安了电信的宽带。于是想利用电信的wlan网络来做代理,让我在宿舍可以用隔壁楼栋的网络。 就像这样:
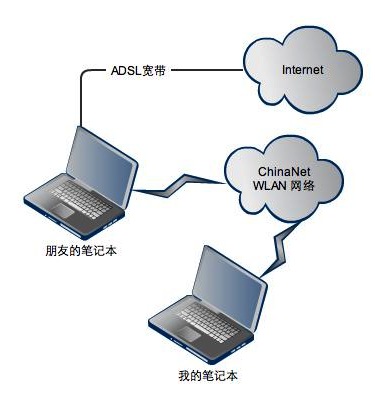
朋友通过有线网卡接入互联网,然后无线网卡连接wlan。然后将有线网卡的网络共享打开,共享网络给无线网卡。无线网卡设置IP地址:192.168.0.1,子网掩码:255.255.255.0,网关:192.168.0.1。 我的电脑连接到wlan之后,设置无线网卡的IP:192.168.0.2 , 掩码:255.255.255.0,网关:192.168.0.1。 这样我就可以上网啦~~~再次狂喜。 在这个方案中,电信的wlan网络被我拿来当交换机了。
然后我拿着我的电脑走到户外,还可以上~~走到我们宿舍所在的楼前面,还可以上~~走进宿舍之后,虽然还连着wlan,但是确无法上网。怎么设置都不行。。。估计是我到了宿舍之后连到了另一个wlan子网(ssid也是ChinaNet)。 但是奇怪的是我把无线网卡设置成自动获取IP,得到的数据确是两台电脑都在一个子网,都可以ping到同一个网关! 其中的原因不得而知,估计是我的接入网知识没学好(毕竟只去上了几节课。。。)
再后来想了个非技术方案,就是不在这里住了!不过这个方案实现起来难度更大~~
直到今天无意在淘宝搜了一下chinanet,想看看是不是有人可以破解这个的。。结果发现很多卖ChinaNet WLAN上网帐号的。各种价格,于是找了一个150元包3个月,每月200小时,然后再赠送2个月~~算下来一个月才30元!! 果断拍下付款。 现在我就是用的电信wlan无线上网~~ 超爽,10M带宽。 那天在我学校往优酷上传视频,100KB以下的速度。今天再尝试,上传速度达到了惊人的1.2MB每秒! 爽啊。。。
果断拍下付款。 现在我就是用的电信wlan无线上网~~ 超爽,10M带宽。 那天在我学校往优酷上传视频,100KB以下的速度。今天再尝试,上传速度达到了惊人的1.2MB每秒! 爽啊。。。
川外成都学院的网络环境太适合电子科大通信工程学子了,在这里可以搞的花样太多了。 不像在我们学校,搞个内网免费帐号,vpn到服务器,直接就可以上网了。 所以鼓励电子科大的同学到川外成都学院找GF,这个学校的女生超多哦,而且质量都很好。
另外推荐一个在线流程图制作网站:http://www.gliffy.com/
完。
偶然看到Volcano发表在http://www.ooso.net/archives/517/的博文,说PHP显示长字符串的时候会导致PHP执行时间超长问题。
正好前段时间研究过HTTP协议,想到可能与HTTP的Transfer-Encoding(数据传输模式)有关。
写了个微博程序。基本需求是:1.无乱码(最好UTF-8)。 2.有输入框可以发布新信息。3.提交后马上可以看到新发的内容。4.必须使用POST方式提交。5.信息后面要有时间标记。6.不能发布任何HTML标签。
<?php
header("content-type:text/html; charset=utf-8");
$a=@file_get_contents(l);
($p=$_POST[s])&&file_put_contents(l,$a='<hr>'.htmlspecialchars($p).date(' Y-m-d H:i').$a);
echo '<form method=post><input name=s></form>'.$a;
?>
运行效果如图:

注释一下:
前段时间心血来潮,想搞个歌词库,于是网上查了一下,发现百度的歌词文件是连续的数字作为文件名( 方便啊)。于是就写了个程序批量搞百度的歌词。
方便啊)。于是就写了个程序批量搞百度的歌词。
程序使用socket方式模拟浏览器去取百度的歌词,速度优化到很快了。 我目前已经下载了百度的91083份歌词啦
百度的歌词文件虽然是数字,但是不是完全连续,中间有些数字是没有歌词的。所以程序显示no的时候,不要觉得奇怪哈。
用法:在命令行下跑。 输入:php baidu.php。 当然,一次肯定是不可能把百度的所有歌词下载下来,所以要分多次。每次下载的起始数字和结尾数字请打开baidu.php编辑。
提醒:下的太快了百度会封你IP。不过过一会就又好了。
前几天做某个hack工程的时候,需要用到.net来编程。要实现一个类似代理的小程序,通过URL传入目标地址,然后通过.net去连接目标服务器下载文件后返回给我的浏览器。
开始什么都不知道,于是请教了一个.net高手,写了一个hello world。于是我开始用C#补充代码,用到了.net的socket编程。再次受到C#那超级恶心的变量类型的摧残。每个变量都必须声明变量类型,烦死了。。比如:
IPEndPoint ipe = new IPEndPoint(address, port);
天哪,谁知道IPEndPoint是什么样的数据类型。
后来想到.net还可以用JS来写,于是就把刚刚写的代码重写了一下。发现JScript相比C#起来有点多多啊。 首先,变量不用声明类型(当然如果引起混淆时候还是要声明的,只是声明方式不同,比如var address: IPAddress;)。其次,在JScript里面可以使用大部分Javascript的方法。比如各种字符串处理方法 等。
据说.net是编译成中间语言再执行的,那么用什么语言来写就没什么区别了。但是怎么觉得JScript在.net里面非常受歧视?msdn里面的示例代码什么都有,就是没JScript的。。。。
本人.net功力尚属入门级,可能我用到的东西太少了。没有体现出C#的强大。( 我觉得我愿意永远不知道C#有多么强大...)
我觉得我愿意永远不知道C#有多么强大...)
完。
以前搞过一段时间的asp,觉得application这个对象很爽。。可以很容易的写一个聊天室。。。后来逐渐转到php,就一直为这事郁闷。。因为php里面没有对应的东西。数据只能往数据库或者文件里面写才能实现共享。 今天在公司做聊天室的时候,灵机一动,居然让我发现了一神奇的方法~~哈哈:
PHP里面的$_SESSION变量可以实现类似Application的功能,但重点在它不能跨浏览器进程,或者说是跨用户。。只能是单个用户操作不同页面时候的变量传递,是一种cookie的替代方案。
众所周知,php里,调用session_start()之后,客户浏览器会收到一个大概名叫PHPSESSID的cookie,这个叫session_id。不同页面的参数共享就是靠这个变量实现的。
有时,由于客户端浏览器或者其他什么神奇的原因,导致无法正常发送 PHPSESSID的时候,我们可以手动发送,然后在php里面的session_start();之前,调用session_id("sessionid在这里");手工指定session_id ,这样,就可以让session工作正常。(比如浏览器不支持cookie,或用flash上传文件的时候)
好了,关键的东西来了。如果我们让每个用户的session_id都一样会怎么样? 哈哈。ASP的Application功能便呼之欲出~~~
实现方法非常简单: 在每个php页面的前面都写上下面的代码: session_id("xxxx"); session_start(); 然后,你就可以像用Application对象那样来使用$_SESSION了。。~~哈哈哈哈~~~爽吧~~
PS:ASP的Application对象是存储在内存里面的,而PHP的SESSION一般默认是用文件来存的。不过也可以设置php.ini让php用mysql数据库存,甚至用memcached来存~~具体方法就不详述了。。 chy提到session本来的作用是保存用户的登录信息等,是非常有用的。我这样一弄,session就失去了它原有的功能。所以我搞了一个函数,可以实现全局session和局部session共存。互不干扰。
/*
用法:
application('key','value'); //设置 key=value
$value = application('key'); //获取 key的值
*/
function application()
{
$args = func_get_args(); //获取输入参数
if (count($args) >2 || count($args) < 1) return;
$ssid = session_id(); //保存当前session_id
session_write_close(); //结束当前session
ob_start(); //禁止全局session发送header
session_id("xxx"); //注册全局session_id
session_start(); //开启全局session
$key = $args[0];
if (count($args) == 2) //如果有第二个参数,那么表示写入全局session
{
$re = ($_SESSION[$key] = $args[1]);
}
else // 如果只有一个参数,那么返回该参数对应的value
{
$re = $_SESSION[$key];
}
session_write_close(); //结束全局session
session_id($ssid); //重新注册上面被中断的非全局session
session_start(); //重新开启
ob_end_clean(); //抛弃刚刚由于session_start产生的一些header输出
return $re;
}
当然,这样操作的成本有点高。。不过在实际使用中,基本不会遇到使用全局session和局部session的频率都很高的情况。所以可以按需求封装局部session或者是全局session。 上面那个函数封装的是全局session,稍微修改就可以实现局部session。
完。